
I am a master's student at Carnegie Mellon University. I work with Professor Chris Donahue on Generative Audio and Professor Bhiksha Raj on Audio Language Models. I am interested in audio understanding and generation.
Previously, I interned with Dr Satrajit Ghosh at MIT and Dr Martin Vetterli at EPFL. I completed my undergraduate degree in Electrical Engineering at IIT Delhi, where my concentration was on signals processing and ML.
Selected Publications and Preprints
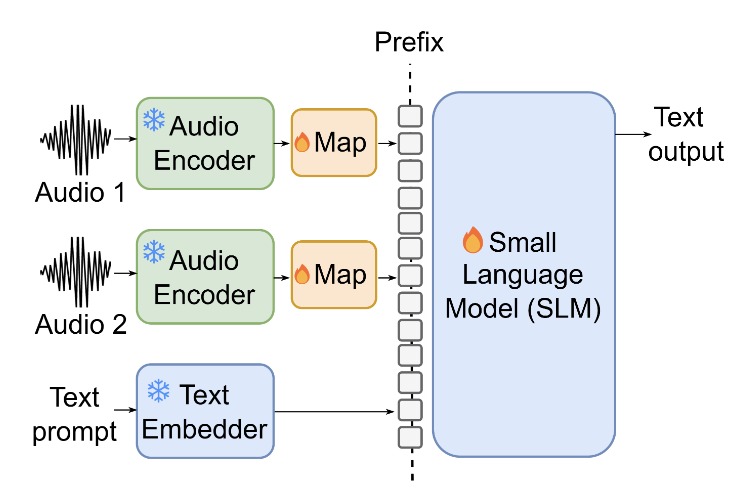
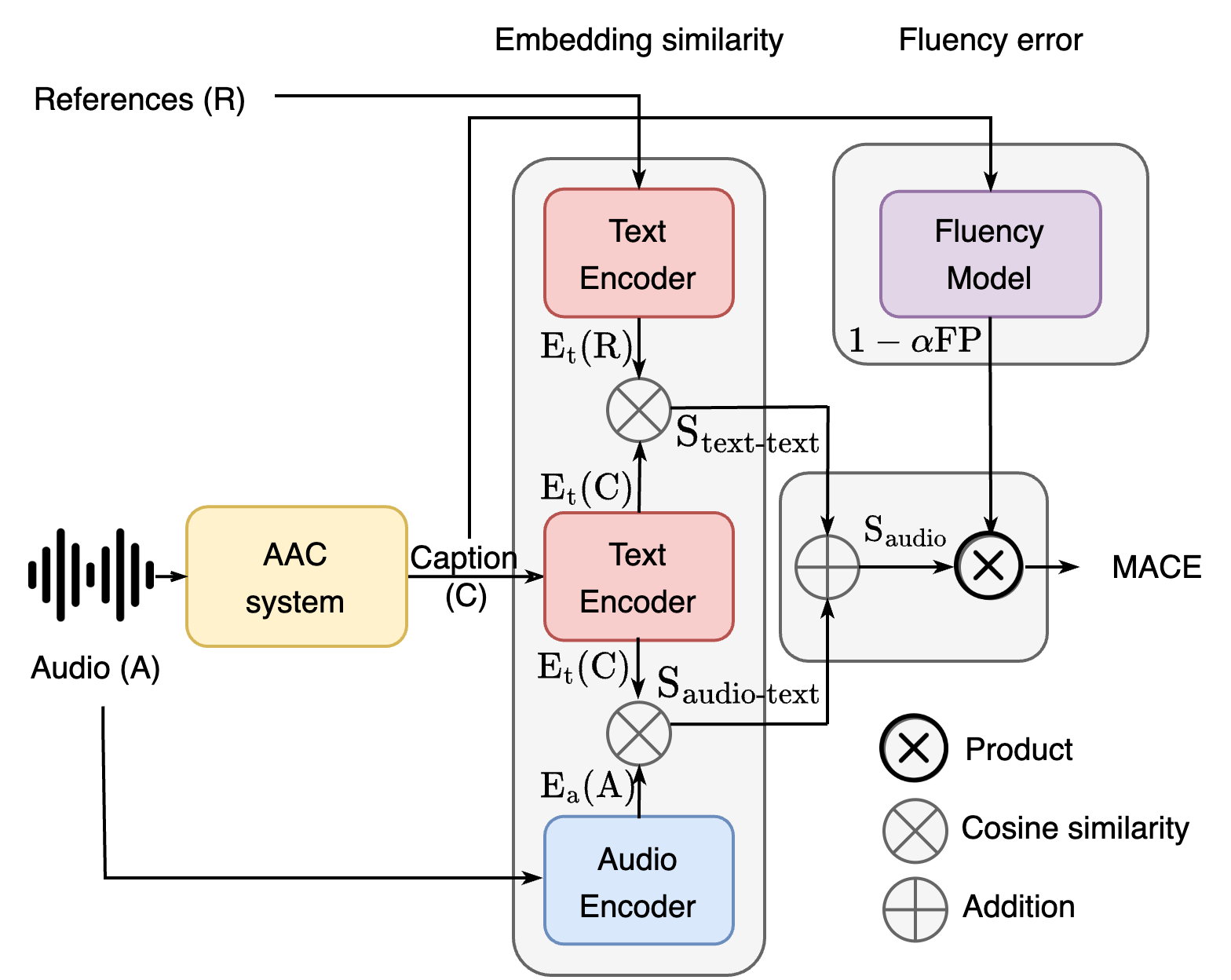

Vision Language Models Are Few-Shot Audio Spectrogram Classifiers
Satvik Dixit, Laurie Heller, Chris Donahue
- NeuRIPS 2024 Audio Imagination Workshop
- Paper
Contact & Links
- Email: satvikdixit@cmu.edu
- Google Scholar: Google Scholar
- LinkedIn: LinkedIn